Very good question? How to start the series, especially since I want to avoid major rants like the introduction was. My first idea was to really dive into the belly of the beast, and tackle one of the major failings of C when viewed from a modern perspective. Strings are a perfect candidate, strings in C being one of the most horrible missfeatures of it. Strings are bad for a lot of reasons that I will get into at a later date, but one of the reasons is that they inherit everything that is bad about C arrays. So tackling arrays first would make more sense. But array are bad due to their design plus the bad API used to handle common task for them. So I would get a huge post again that tries to tackle too much at once. Plus doing all the coding would take too much time.
Diving into advanced topics without presenting syntax may seem strange, but it is a widely used approach. A lot of programming books have a first chapter that walks you through a large set of features as an introduction. But since I’ll skip arrays and memset for now, maybe I could do a post about syntax. But I found this boring to write and read, since in my introduction I made a huge case out of how syntax is very important, but getting hung up on small details is just silly and this potential post would be about the small details.
So I’ll talk about definitions and dependencies, touching just a little bit on syntax and going into circular dependencies. The way a language handles modules is a vital point, which C handles the same way it handles most of its “features”: it has zero support for it and misuses another feature to give a workable but often problematic solution. C has no module support (and passes on this lack to C++) and uses the precompiler to stitch together a forward declaration system and the linker to handle the final processing and merging of your object files. You compile every single source file separately and then the linker puts them together, often causing link errors when something is not found or repeated. This would never happen with a module system. A lot of programmers are not aware how rudimentary this system is, how little C does when compared to any modern (and a few old) alternative, because by having a good and consistent convention you can mask a lot of the problems. But still: how many times have you had problems including headers, especially from third party components? If your answer is “never”, then either you are part of a very lucky minority or never had to work with huge code bases.
So having a good module support is essential for a language and thus for Z2. Another facet of a module system is how you handle modified sources, updated incremental builds and search for other modules. For C and Linux, one usually uses “make” or a more advance IDE. Make is a simple but generally good tool for automating some tasks. But it is particularly poorly suited for the needs of C, so a more powerful tool is needed. This is where “autotools” and friends come in. A.K.A. the Antichrists! Yes, plural! I will not talk about autotools in fear of my head exploding due to sheer cranial pressure induced by massive rage. Maybe I’ll write a post in which I systematically analyze and give arguments why autotools and friends and any other tool that uses the same principles are not the right tools for the job.
But the conclusion is that the Z2 compiler will handle these tasks for you. Sure, you will still need to tell it where to search your file system for the modules, and you will be able to use shell scripts or autotools or whatever to do that, but the actual building is handled by Z2. You will be able to only tell it the location of your main source file and the compiler will handle everything, locating every module automatically that is in the “object search path” and only compiling what is needed based on timestamps. As an added bonus, it will only pull in definitions once per module and compiler sessions. Look at any compiler time break down and you will see that the preprocessor ends up taking a disproportionately large chunk out of the total compilation time. Headers get pulled in and preprocessed in every compilation unit. Add to that C++ template instantiation and you will see why compiling C++ is so slow. There is this myth that C++ compilers are extremely fast. And this is true, but they have to do so much more than compilers for other better designed languages that the end result is a lot worse.
So C has zero module support, it uses external clunky tools that have (and need to have) a huge pile of flaming ancient wisdom in order to be portable and it uses the preprocessor to handle definitions while not having any built in mechanism to do this or even prevent multiple definitions. And we did not even get to the capabilities of the compiler itself. Which are lacking again. There are multiple ways to handle the act of locating definitions of items in different locations of the code, and C does the most basic of them: take them in order. And when this is not possible, uses forward/extern declarations and header files. Based on moving around blocks of text. The compiler can only refer to entities that it has encountered before in the linear process of compiling a single file.
Finally, here we are at the topic of this post! After two pages of ranting! Z2 being a research compiler, I will be doing the very opposite of what C does: full circular reference resolution. There are other methods that use some slight compromises, getting better performance, but this is not essential for our needs. The compiler will be able to reference any object that is included in the module or other modules that are used by the current one, without the programmer having to think about how to assure visibility by manually placing items at key locations. This feature can be abused by programmers, making things unreadable, but I am going to assume that you are working with people with good intentions that will structure programs in a readable fashion. And since this post is already too long, I am only going to talk about the resolution of constants, leaving variable for another time. Even as such, the topic of constants is going to be a two part post.
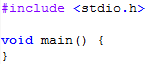
Let’s get to the first snippet of code. Since doing text formatting on Blogger is not that easy, I’ll use pictures to allow for better syntax highlighting and indentation:

Do not worry about the syntax. Z2 supports multiple levels of detail when expressing what you want the compiler to do, and I will generally be using the most spartan one available. Still, it should be quite readable to anyone. On the first line we are pulling in a module. This is actually a normal C header, not a Z2 module, which is why it ends with “.h”. This is temporary and used only until we can get a minimal standard I/O module rolling. Then we declare a class called “Foo”, which has a single constant called “Bar”. I am intentionally using ambiguous naming conventions. More on this later. And finally, and empty main method. You will notice that there are no semicolons at the end of statements. This should be familiar to people who use modern scripting languages. A lot of people use them for rapid prototyping, automation and other small tools. I tend to use C++ for these tasks with the aid of powerful libraries but I do sometimes use Python or Ruby. Whatever the case, there is one thing I do not miss: semicolons. When designing something, generally speaking, it is good to cater for the most frequent use scenario. The overwhelming majority of statements in most programming languages are one liners. Sometimes you need to extend to more lines, but there are a lot of good alternatives to semicolons that do not cause ambiguity and even more that cause. There is a huge class of languages out there that get by perfectly without semicolons as statement terminators and including them in Z2 feels like an anachronism.
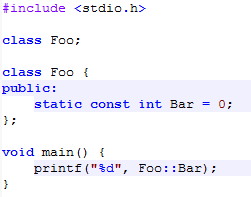
Now let’s see what the equivalent generated C++ code looks like:
Hmmm, a lot shorter. I put great value on compilation speed and I try to avoid making both compilers do the same job. Z2 has already handled the entire source code and determined that it should eliminate both the constant and the class. There is no need for the backend, in this case C++ (and all other cases for the foreseeable future) to parse the class only to decide that it is not needed. Now, let us actually use the constant. I will also use this opportunity to show you a more verbose syntax that is semantically identical to the first one, but more explicit, giving information that the compiler can figure out on its own:

The constant “Bar” now has an explicit type. In the first sample I left the compiler figure out the type of the expression, but this time I have chosen to give it explicitly. I also gave the return type for the “main” method. One thing you will notice both from the naming conventions and the syntax highlighting is that types, including “built in” types like integers start with a capital letter. Z2 is class, value, reference, copy and move centric (I’ll explain all these keywords in the future), thus everything is an object. Like in most dynamic languages. But the difference is that the objects actually map to true hardware types when possible so there is no performance penalty involved. Even though normal integers are called “Int” and the declaration of this class is available in text form to the compiler in the same manner as “custom” classes are, and Int has a bunch of constants and methods, after compilation Int is mapped to a 32 bit signed integer and is no different from “int” in C. “printf” is also not the normal printf, but it is enhanced so it understands the types of the parameters it is getting and you will be able to get the same behavior for any function without any hardcoding or the compiler understanding or treating I/O or varargs specially.
And C++:
This time the definition of “Foo” has been pulled in. We have a forward class declaration section after the include directive. I could avoid this, adding classes that are only needed but right now it does not seem worth the effort.
Now let’s do dome circular constant initialization:

Yikes! What is that? A = A (= is assignment)? This makes sense for variables, but not for constants. This is obviously a compilation error and should be signaled as such. I could signal it as an “undefined identifier error”, but instead you get this:
The two numbers after “error” give us the line and column of the error: 4 and 11. At these coordinates we have exactly the beginning of the constant “A”. Then the compiler informs us again that something is wrong with “Foo.A”: a circular constant initialization. It also informs us that I make spelling errors. I noticed too late that I spelled the error message wrong and I ma not redoing the screenshot. Then we get the breakup of the cycle: the constant “Foo.A” form the file “0103.zsr” at coordinates 4, 11. So the value of A from the first coordinates is dependent on the value of A from the same coordinates. This makes a lot more sense if we consider a more complex example:

The first constant, “A” is initialized properly. But when initializing the rest of the constant chain, the programmer made a mistake: instead of initializing E with “F % 4”, it was initialized with “C % 4”, thus creating a circular reference. And this is what the compiler tells us, but in its own words:
I couldn’t go on without correcting Foo:


You will notice that the constants have been evaluated and we only get the final result in the C++ file. As said, I do not want both the Z2 compiler and the backend compiler to do the same computations. But the main reason for this is that there is no way C/C++ can handle such constant initializations because they expect a linear progression of value dependencies and Z2 does not have such a progressions. There are multiple cases where one cannot reorder the constants when dealing with multiple classes. One would need to break up the classes and/or insert dummy constants to make C happy. Using evaluated values hits two birds with the same rock. And the results are equivalent in both cases.
I hope that the advantages of this constant system are clearly visible. The word “class” may make you think about OOP, but here we are actually creating a named constant repository. An absolute repository that grants its values to everyone to use, including other constants. And it has no troubles initializing values based on values that were not encountered before as long as they are initialized somewhere else. This is similar to the way human minds work. Let’s say you are using C and the constant M_PI a lot. After using it for an extended time, you notice that you use the expression “2 * M_PI” a lot, so you decide to create a new constant “M_2PI”. If someone asks you what the value is, you answer “two times M_PI”, without actually stopping to think what value Pi has. And if you use M_2PI exclusively for extended periods of time, you (or a programmer new to the project) may actually write “M_2PI / 2” when Pi is needed, associating the desired value with one you are overly familiar with. The human mind is not as ordered as a compiler that can only see statements encountered until it has reached the current line. Here is the problem in other words: I care about giving constants a symbolic name. Only the name is important. The value can change. I am in charge of naming and giving straight forward values to them. The compiler is in charge of figuring out the values when computations are needed. Classes as abstract constant pools do not care about order since you cannot reinitialize a constant.
The only problem here is that I have intentionally left the scoping rules ambiguous and I did not impose a coding convention and thus it is easy to image a scenario that might cause problems, like when “B” is both a constant in the current class and the name of a different class. I will give clear scoping rules in due time. Right now I want to focus on the little things first.
I would also like to point out that Z2 outputs proper C++ code only for convenience reasons. It would be trivial to make it output other types of code, but some languages are more problematic. Without classes or namespaces, Foo::A would look something like Z2_C__Foo__A or some other mangled name in C. But with time I’ll add this option too. As stated in the first post, a LLVM backend would make the most sense and translating to C++ is just the fastest solution right now, not the ideal one.
This concludes the first part of this topic. In the second one we’ll have more fun, this time initializing constants across classes, checking out again circular references and doing an extensive benchmark. For the benchmark I am thinking about using several MiBs of constant definitions in multiple classes/files and seeing how fast we can compile, the size of the resulting translated file and memory consumption. In the next post I’ll try to be more structured and slowly migrate away from the “huge block of ranting” model, but the plan is for Z2 posts to be around 5 pages a piece, so do not expect short posts like for DwarvesH.
Your diligence to your work and project gives me a hard on.
ReplyDeleteBut in all seriousness, the amount of sheer work and time you invest in this with little to no recognition is commendable. The fact that you update us very frequently is a major plus.
I'll be sure to spread the word and hope you are recognized for what you do. Keep up the good work! There are many eyes on you. Stalker intended.